Redis学习
Redis简介
关系型数据库
指采用了关系模型来组织数据的数据库。
关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
主流的关系型数据库有:Oracle,Microsoft SQL Server,MySQL,PostgreSQL,DB2,
Microsoft Access, SQLite,Teradata,MariaDB(MySQL的一个分支),SAP
优点:
- 容易理解:关系清晰。
- 使用方便:通用的SQL语言操作关系型数据库非常方便。
- 易于维护:丰富的数据完整性,减少了数据的冗余和数据不一致的概率。
缺点
拓展性低
性能低,多表关联查询导致性能欠佳。
数据库事务必须具备ACID特性
Atomic 原子性
原子性是指事务包含的操作要么全部成功,要么全部失败回滚。
Consistency 一致性
一致性是指事务必须使数据库从一个一致性状态转变到另一个一致性状态,也就是说一个事务执行之前和之后都必须处于一致性状态,例如:用户A和用户B两者的余额加起来一共是4000,那么两者之间不管如何进行转账,最终两者余额总值依旧是4000。
Isolation 隔离性
隔离性是指多个事务之间自身的操作是隔离的,不会互相影响。
Durability 持久性
持久性是指一个事务一旦提交了,那么对于数据库中的数据的改变就是永久性的,即使在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
非关系型数据库(NoSQL)
指非关系型,分布式的,且一般不保证遵循ACID原则的数据存储系统。
非关系型数据库采用键值对存储,且结构不固定。
特点:
- 可扩容,可伸缩
- 大数据量下高性能
- 灵活的数据模型
面向高性能并发读写的key-value数据库:
主流代表有:Redis, Amazon DynamoDB, Memcached,Microsoft Azure Cosmos DB和Hazelcast
面向海量数据访问的面向文档数据库:
主流代表有:MongoDB,Amazon DynamoDB,Couchbase,Microsoft Azure Cosmos DB和CouchDB
面向搜索数据内容的搜索引擎:
主流代表有:Elasticsearch,Splunk,Solr,MarkLogic和Sphinx
面向可扩展性的分布式数据库:
主流代表有:Cassandra,HBase,Microsoft Azure Cosmos DB,Datastax Enterprise和Accumulo
CAP理论
NoSQL的基本需求就是支持分布式存储,严格一致性与可用性需要互相取舍
CAP理论:**一个分布式系统不可能同时满足C(一致性)、A(可用性)、P(分区容错性)**三个基本需求,并且最多只能满足其中的两项。对于一个分布式系统来说,分区容错是基本需求,否则不能称之为分布式系统,因此需要在C和A之间寻求平衡。
C(Consistency)一致性一致性是指更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。与ACID的C完全不同
A(Availability)可用性可用性是指服务一直可用,而且是正常响应时间。
P(Partition tolerance)分区容错性分区容错性是指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务
Redis 简介
Redis (REmote DIctionary Server) 是使用C语言开发的一个开源的高性能键值对(key-value)数据库。
特点:
- 数据间没有必然的关联关系。
- 内部采用单线程机制进行工作。
- 高性能。
- 多数据类型支持
- 字符串类型 string
- 列表类型 list
- 散列类型 hash
- 集合类型 set
- 有序集合类型 sorted_set
- 持久化支持,可以进行数据灾难恢复。
Redis 应用
- 为热点数据加速查询(主要场景),如热点商品、热点新闻、热点资讯、推广类等高访问量信息等
- 任务队列,如秒杀、抢购、购票排队等
- 即时信息查询,如各种排行榜、各类网站访问统计、公交到站信息、在线人数信息、设备信号等
- 时效性信息控制,如验证码控制、投票控制等
- 分布式数据分享,如分布式集群架构中的session分离
- 消息队列
- 分布式锁
Redis 数据存储格式
Redis 自身是一个Map ,其中所有的数据都是采用key-value的形式存储
key部分永远都是字符串,Redis 数据类型指的是value部分的类型
String 类型
存储的是单个的数据,最简单的数据存储类型,也是最常用的数据存储类型。
存储格式是:一个存储空间保存一个数据
存储内容通常使用字符串,如果字符串以整数的形式展示,则可以作为数据操作使用
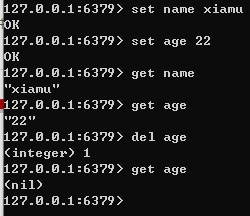
例如:
key value
name ——–> xiamu
age ——–> 22
string 类型数据的基本操作
添加/修改数据
set key value
获取数据
get key
删除数据
del key
例如:
添加/修改多个数据
mset key1 value1 key2 value2
获取多个数据
mget key1 key2 …
获取数据字符个数(字符串长度)
strlen key
追加信息到原始信息后面(如果原始信息存在就追加,否则就新建)
append key value
缓存雪崩
问题分析
短时间内有大量的key集中过期,新的缓存还未到来,因此所有的请求都去查询数据库,从而对数据库CPU和内存造成巨大的压力,严重的会导致数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃。
解决方案
构建多级缓存架构
Nginx缓存 + Redis缓存 + ehcache缓存
检测Mysql严重耗时业务时对其进行优化
对数据库的瓶颈排查:例如超时查询,耗时较高的事务等
灾难预警机制
监控redis服务器性能指标
- cpu 占用和使用率
- 内存容量
- 查询平均相应时间
- 线程数
限流、降级
短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步访问放开访问。
缓存击穿
问题分析
Redis中某个key过期,这个key访问量巨大
多个数据请求从服务器直接压到Redis后,均未命中
Redis在短时间内发起了大量对数据库中同一个数据的访问
解决方案
预先设定
对于一些高热的数据信息可以预先加大这些key的过期时长。
现场调整
监控访问量,对自然流量激增的数据延长过期时间,或者设置为永久性key。
后台刷新数据
启动定时任务,高峰期来临之前,刷新数据有效时间,确保不丢失。
二级缓存
设置不同的失效时间,保证不会被同时淘汰就行。
加锁
分布式锁,可防止被击穿,但慎重使用。
缓存穿透
问题分析
获取的数据在数据库中也不存在,数据库查询未得到相应的数据
Redis获取到null数据未进行持久化,直接返回
下次此类数据到达重复上述过程
出现黑客攻击服务器
解决方案
缓存null
对查询结果为null的数据进行缓存(长期使用,定时清理),设定短时限。
实施监控
实时监控redis的命中率与null数据的占比。
key加密
布隆过滤器
将数据库中所有的查询条件,放入布隆过滤器中,
当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
布隆过滤器原理:
原理就是一个对一个key进行k个hash算法获取k个值,在比特数组中将这k个值散列后设定为1,然后查的时候如果特定的这几个位置都为1,那么布隆过滤器判断该key存在。
布隆过滤器可能会误判,如果它说不存在那肯定不存在,如果它说存在,那数据有可能实际不存在
参考:




